Corpora compilation for prosody-informed speech processing
My article “Corpora compilation for prosody-informed speech processing” was finally published in Language Resources & Evaluation journal (LRE) after a long period of back and forth with the reviewers. The paper is like a TL;DR (too long didn’t read) version of my thesis where I give a summary of all the tools, datasets and experiments that came out of my PhD research, which dealt with the basically the question: How can we incorporate non-verbal information like prosody in machine translation and transcription?
For those who read “prosody” twice there, it refers to the “music-like” aspects in speech, which correspond to intonation, rhythm and stress. While words carry “what” is said in an utterance, prosody deals with “how” they are delivered.

In this post, I’m giving a further TL;DR for the fast researchers out there. You can follow links to respective papers and libraries if you’re interested.
Prosodically annotated TED Talks
To begin my studies, I needed a big corpus to study and train machine learning models based on prosody. I created Prosodically annotated TED Talks (PANTED) corpus based on my supervisor Mireia Farrus’s version and augmented with additional prosodic and syntactic information.
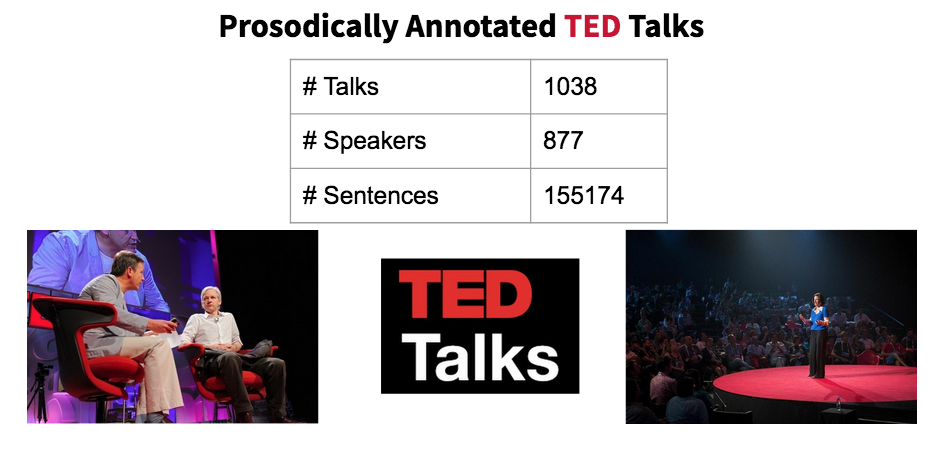
Punctuation restoration with prosody
The whole reason behind creating PANTED was to see the effect of prosody on the punctuation restoration task. It showed that pausing and intonation information can improve the automatic punctuation of ASR output. (Original paper, punkProse code)
Proscript
At some point, I realized how painful it was working with Praat and TextGrids when doing machine learning, so I created my own data structure and visualizer. Proscript helps represent speech with segment-level prosodic features in a tidy CSV file. Python library in Github.
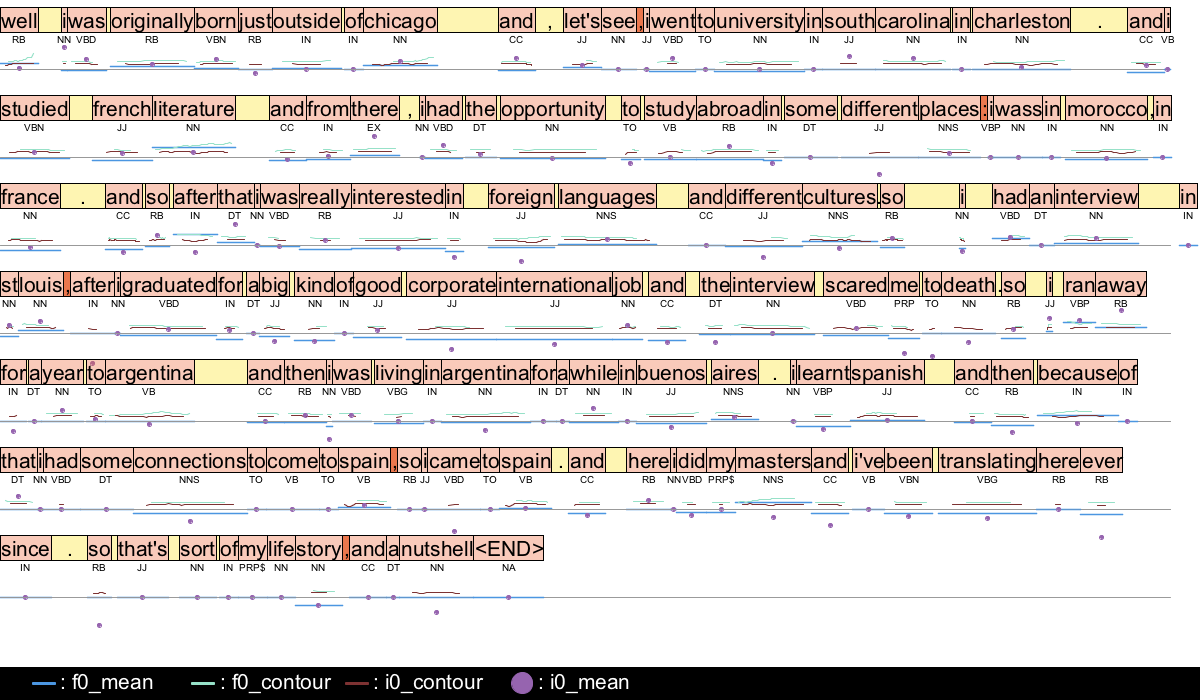
Prosograph
Prosograph enables manual examination of Proscripts along with their audio by visualizing speech-related characteristics besides words similar to a musical scoreMusical score. It’s programmed in Processing and is accessible from github.
movie2paralleDB
I wanted to go into translation from the beginning of my PhD, although I knew it might be a bit tough. Not having any parallel speech corpora around didn’t stop me of course. I built movie2parallelDB to make corpora automatically, out of dubbed movies and series.
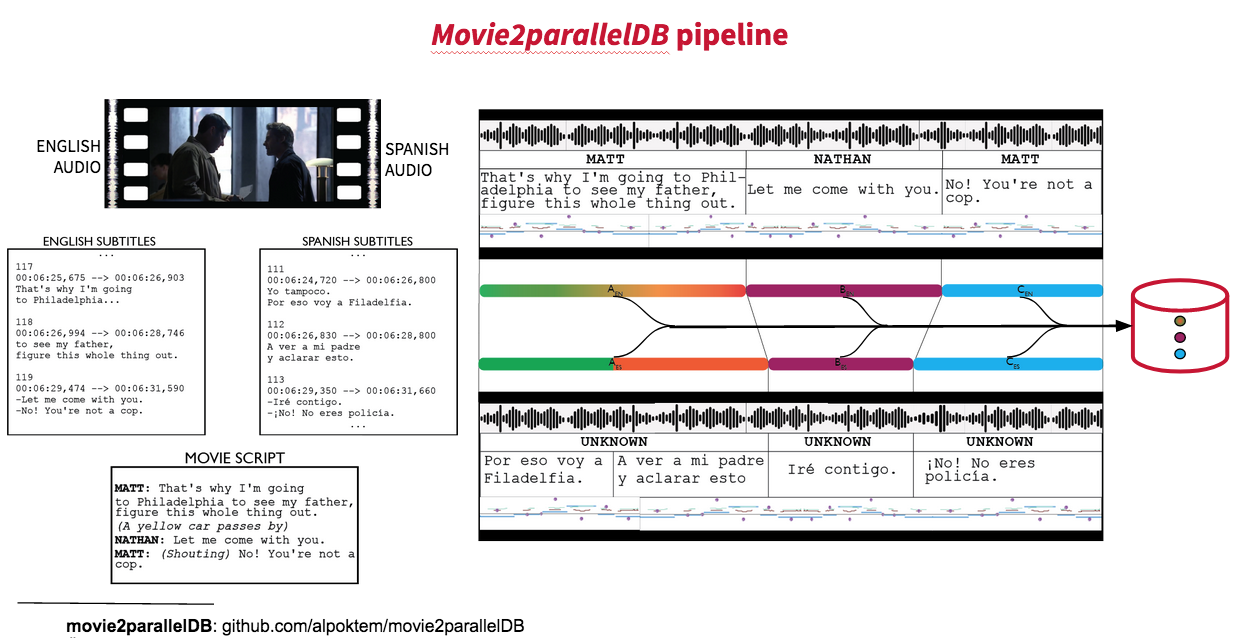
Heroes Corpus
The result of this was Heroes corpus, an English-Spanish parallel movie speech corpus made out of my childhoods popular series Heroes. We showed in the paper how silence information can improve spoken machine translation.

I also earlier explained about how I used this corpus in building a prosody-informed machine dubbing setup.