Towards realistic machine dubbing
In the paper Prosodic Phrase Alignment for Machine Dubbing that I co-authored with my PhD supervisors, we explored how to achieve lip-syncing in automatic multimedia translation. In this blogpost, I’ll explain our methods and findings in a bit more audiovisual way, which I believe the nature of the work deserves.
Automating multimedia translation has become increasingly relevant in the age of user-generated content. The popular video sharing site YouTube provides automatic subtitling with the push of a button, enabling it to be accessible to audiences of different languages.
Although subtitles may work in many occasions, it is not always the preffered translation medium. Certain countries, for example, prefer watching foreign movies dubbed into their language. Also, subtitled content rarely help the accessibility for children or viewers with reading difficulties.
Automatizing dubbing though, hasn’t really made it to widespread usage yet. Compared to subtitling, it involves additional auditory and visual dimensions which makes it a rather more complex process. Dubbing, as a type of audiovisual translation, takes care of many more aspects than mere translation and timing. These include, matching the voice of the character being dubbed, finding translations that fit within a certain time span and also achieving realistic alignment of the dubbed audio with the lip movements of the on-screen characters. This process, which is called lip-syncing, has various aspects associated with it:
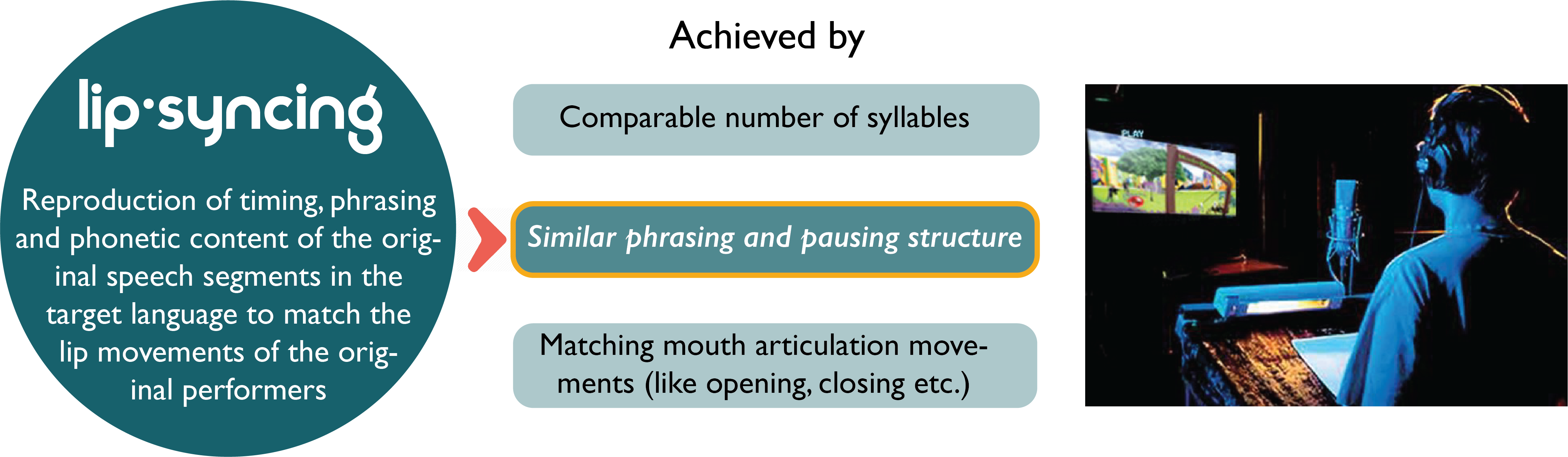
If we were to imagine a system for automatic dubbing, the translation framework should give attention to these dimensionalities. It should not only accomplish the translation of the linguistic content, but also deliver it within a comparable prosodic structure that makes it align with the visual content.
Machine dubbing
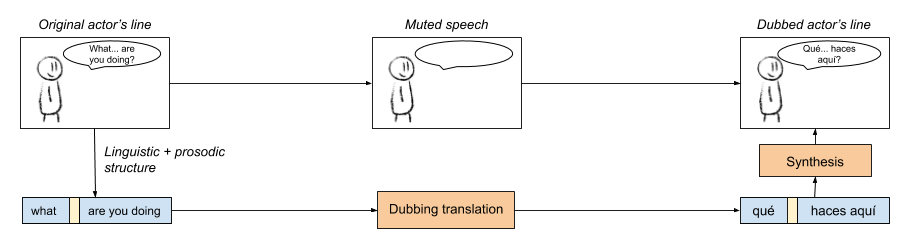
A rough automatic audiovisual dubbing pipeline
The diagram above shows a simple scheme of the audiovisual translation process. The dubbing translation analyzes the input speech both in terms of linguistic content and its prosodic structure. Following, its translation is synthesized respecting the same prosodic structure and then placed over the muted version of the video. We aim to achieve coherence between actor’s lip movements and the synthesized audio by respecting the prosodic phrasing structure of the actor’s utterance.
To illustrate with an example, let’s take a scene from the TV series Heroes, where one of the show’s characters Daniel (Malcolm McDowell) utters the following line. (Click on the image to watch the actual scene)

A English-to-Spanish neural machine translation system translates this sentence as below. It is not perfect but gets the message.
Has hecho mucho por nosotros. Hemos hecho mucho por ti.
Tanto que no podíamos hacer para ti, si te vas a abandonar.
If we were to dub this segment, we could use our Spanish text-to-speech system (TTS) and place the output on the video following our machine dubbing scheme. However, to achieve realistic alignment between the synthesized translation and the video, we should somehow condition the synthesis to respect McDowells’s phrasing of the line.
Visualizing his utterance where yellow boxes indicate pauses, the synthesis of the translation should go a bit like below.

The challenge here in obtaining a synchronized synthesis is not only to fit within the time interval he is speaking. He structures his speech into prosodic units which are enclosed within an intonational structure and terminated with a pause. If the synthesized speech doesn’t synchronize with these sub-phrases, it would give an unrealistic feeling since his lips are not moving during these paused intervals.
Performing this automatically would require the following: (1) Detecting the prosodic phrases (words and timings) in the input sentence, (2) Mapping them to meaningful portions of the translation output, and then finally (3) synthesizing them with the timings we get from the input sentence.
To illustrate these steps on the rough pipeline introduced earlier:
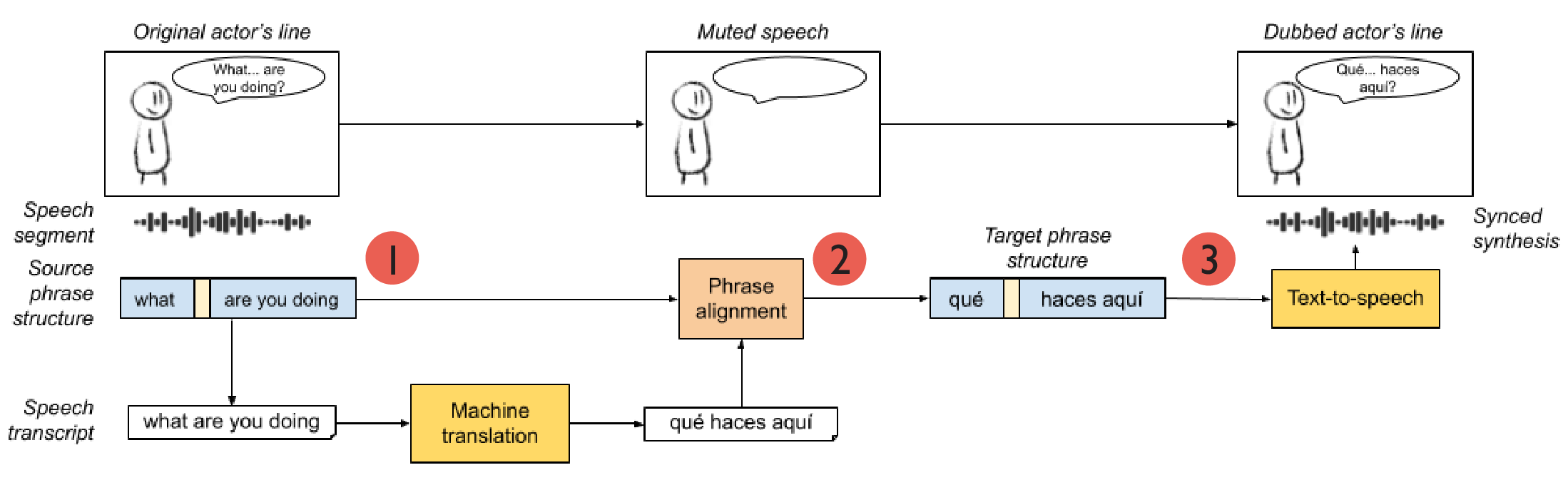
Detailed machine dubbing pipeline
Detecting of prosodic phrase structure
The first step is to detect the phrases in the input sentence. As we define prosodic phrases as pause terminated subphrases in a given utterance, we need to know the timings of each word and also the length of silence between them. If the transcript of the speech segment is available, this is easily done with a forced alignment algorithm.
This was already performed on our data coming from Heroes Corpus, which is a collection of short segments from Heroes series. Each segment in this dataset consists of audio of an actor’s line, its subtitle transcription and word timings obtained with a forced alignment tool. The excerpt above is a sample from this dataset.

Word and pause timings obtained with a forced alginment algorithm
In order to differentiate between articulatory effects and linguistically motivated pauses, a pause duration threshold of 250ms is considered as a prosodic phrase boundary. Following this approach, we end up with the following phrase structure from our example:

Input segment structure with prosodic phrase and pause durations
This structure gives us all the timing information we need on how to condition our sythesized translation. We just need to inform the synthesizer of these time constraints for when to speak and when to stay silent. This in turn would sync with the video as the lip-movements are naturally aligned to the speech activity.
However, deciding on which words in the translation to align with which group still remains a challenge.
Cross-lingual phrase alignment
Second step in the pipeline is to find groupings in the translated sentence that more or less match with the input phrases we detected. This is basically an alignment problem, where the aim is to label each word in the translation output with the source prosodic phrase it aligns well with.
Neural machine translation has a mechanism that gives information on the alignment of source and target words. This mechanism called attention is designed to learn the relevance between parts of input and target sequence in training. As a by-product during inference, it can be used to obtain alignment information between the source and the predicted sentence.
A look at the attention matrix visualization gives a hint of this phrase alignment. For our example, we can see the projection of each input phrase on the target word sequence by tracing where the attention weights fire the most.
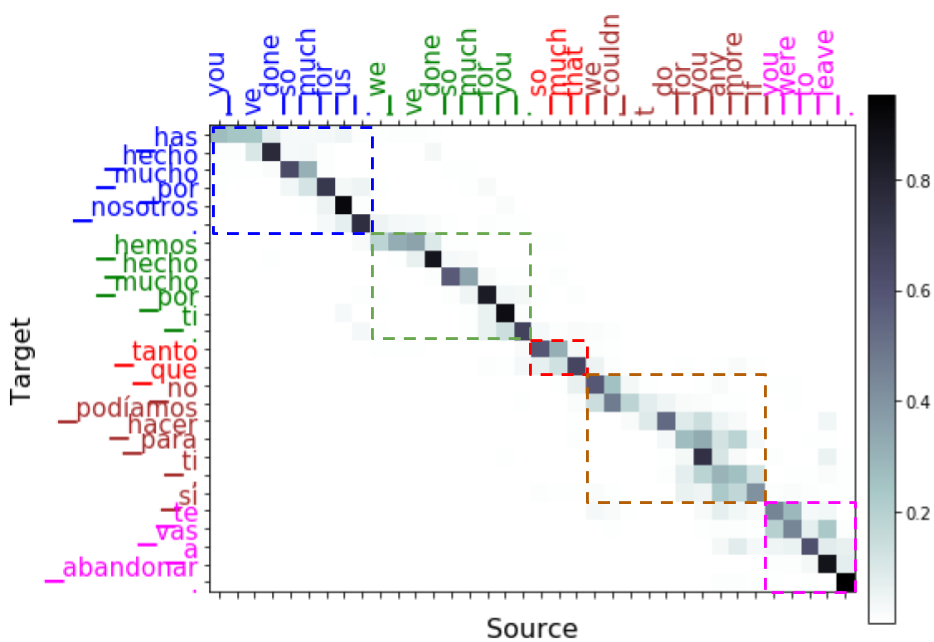
Attention weights are higher in the areas where source and target phrases align.
The challenge of this step is to draw those boxes automatically for the predictions we get from MT. In order to do that, we came up with a scoring algorithm which uses the matrix weights and decides on the most optimal alignment. The procedure that consists of three phases, (1) population, (2) scoring and (3) ranking is illustrated in the animation below:
Conditioning TTS
The third step is to carry on with the synthesis of the translation with the target phrasing structure we just found. To do this conditioning, we follow a method that I call synth bending.
The procedure is as follows: Translated phrase is first sent to a classic off-the-shelf TTS back-end. The TTS back-end computes a sequence of phonemes and silences together with their timings. Secondly, these default timings are bent, i.e. sped-up or slowed-down, according to the timings of the source phrases and pauses they align with.
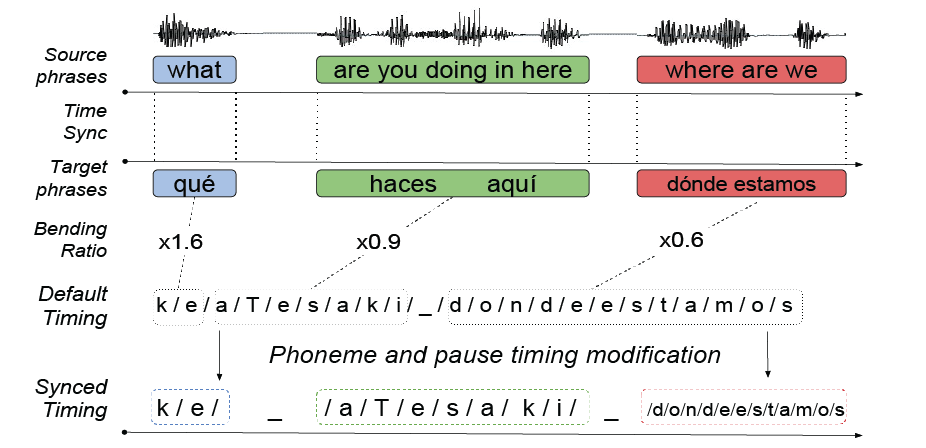
Synchronization by bending phoneme timings
For each phrase, a bending ratio is calculated by dividing the desired phrase duration by the duration of the corresponding phoneme sequence the TTS back-end predicts by default. Each phoneme duration is then multiplied by the ratio of the phrase it belongs to. Silent tokens are made to match exactly the pause duration they correspond to.
Finally, the phoneme and pause sequence with their modified timings is sent to the TTS front-end. This gives us the synthesis of the translated phrase with the prosodic phrasing that is dictated by the source utterance.
The dubbing process is complet once the synthesized audio is placed on top of the muted video. The final pipeline that illustrates all these processes in detail is as follows:
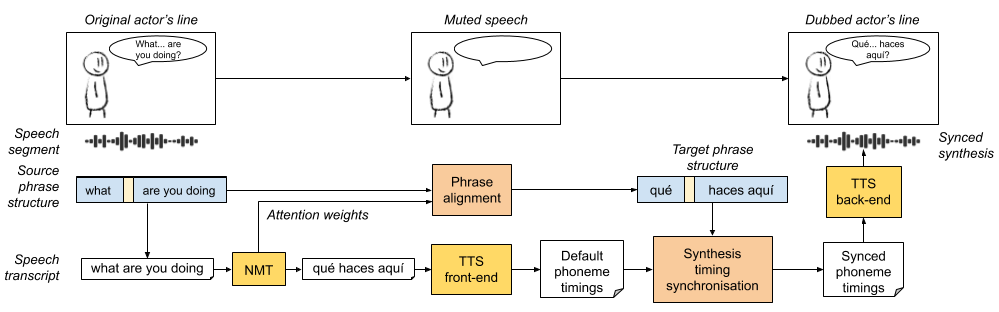
Final machine dubbing pipeline
Evaluation
Some 10 samples were allocated to test out how well the methodology works. They can be found in the project repository together with the original segments. Here’s how our machine dubbed example segment looks like at the end:
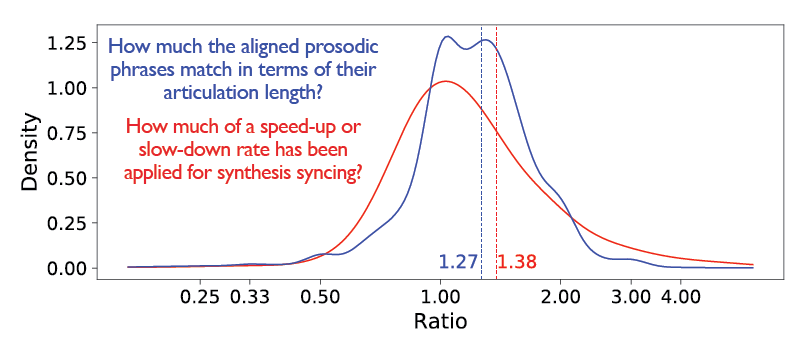
Quantitative analysis was performed on the testing portion of the corpus. We wanted to see how they compare with the professionally dubbed versions in terms of alignment. One metric to help measure this is speech rate, which is the amount of syllables that fall into each unit time. To perform a comparison, we first calculated the speech rate ratio between the original and Spanish dubbed versions in our dataset, which came out to be 1.31. That is, for each English syllable, 1.31 Spanish syllables are uttered in the professionaly dubbed translations. Next, we did the same analysis with the machine dubbing translations and observed a very close figure, 1.27.
Although this similarity shows that in average it converges well, it doesn’t mean that every aligned segment would give this value. We observed that some segments that were sped-up or slow-down above a certain ratio lead to unnatural sounding syntheses. This is particularly observed when the MT output is poor or is uncomparable to the source phrase in terms of its length.
Below is a density graph of the speech rate ratios (blue) and bending ratios (red) calculated for each matching prosodic phrase in the evaluation set. Mean values are shown with dashed lines.
Achievements, shortcomings and beyond
This work can be considered as one of the first on the case of lip-syncing in a translation framework. We leveraged using of auditory features and the process of translation itself to achieve partial lip-syncing, on the basis of speech activation.
The results show the usefulness of a phrase alignment mechanism built on the attention layer output of neural MT. However, we designed a scoring mechanism only to address the alignment of spoken phrases. This is an important dimension in lip-syncing but definitely not the only one. Further lip-syncing guidelines concerning mouth articulation movements are left unadressed. Future work calls for the inclusion of this aspect into the scoring mechanism so that the mouth opening and closing movements align with the appropriate phonemes.
Another aspect we noted is the importance of obtaining a comparable length in the translations. For that, it is essential to condition the MT to output translations that match the length of the source phrase. Alternative translations could also be included in the scoring mechanism, thus leading to a larger set for optimization.
In an applied perspective though, there are many more challenges ahead for machine dubbing. In order for these methodologies to arrive to a useful point, I foresee two major lines: One of them would involve the task of carrying spectral characteristics of the actors’ voices into the synthesis so that they actually sound like themselves, only in another language. And last but not least, especially in movies or TV shows, there is an abundance of prosodic expressivity conveyed with a combination of prosodic traits: intonation, rhythm and stress. A proper spoken translation setup needs to cover the transfer of these features as well.