Personal highlights from EMNLP 2020

In this post I tried to compile some nice papers that I came across in EMNLP 2020 together with the work that I collaborated with. I’ve curated the list with a focus on machine translation and transcription of under-represented languages.
Some personal notes first: This conference was a first for me in a couple of ways. Firstly, it was the first major NLP conference that I participated. Secondly, it was my first fully-virtual multi-day conference. Despite a couple of technical hick-ups, I found the virtual setup to function rather well for me connecting from my cozy home. It’s really nice to see that it is possible to organize events of this scale given the circumstances of the pandemic.
Although, I have to say the experience was incomparable to a presential conference. Strolling through links, chatboards and virtual environments barely replaces the constant flow you experience in the physical conference setup. I am looking forward to see hybrid setups in the future combining presential and virtual participation. I actually believe a virtual alternative has long been due for conferences, regardless of the pandemic. Why? First, virtual participation allows saving a tons of carbon generated from avoidable travel. Second, it is a half-way remedy for researchers that face financial, parental and visa restrictions.
Regarding the content, I was very very happy to see this amount of work on the under-resourced language spectrum. Though, I am probably biased since that was the kind of work I was looking out for. I am not so sure of the diversity of languages represented in the conference. I would love to see a report on that the coming days.
I’d like to start the list with the work that I have collaborated with. Both are motivated by the purpose of bringing NLP and language technology to marginalized and under-represented languages and gives me hope and inspiration for the future of NLP research. I am looking forward to see more and be part of transversal and disruptive collaborations like these.
Masakhane - Participatory Research for Low-resourced Machine Translation: A Case Study in African Languages (Paper, Keynote video)
Masakhane is a cross-border, inclusive, grassroots organisation with a decolonial mindset and a stand against the inherent professionalism, anglo-centricity and academic dominance in the NLP field. They promote a participatory and accessible NLP research methodology and showcase it for languages of Africa. A continent that has been unfortunately but unsurprisingly left mostly blank in terms of coverage in NLP research. The paper rejects the notion of “low-resourcedness” as a mere question of data availability and brings into light many aspects that drive a language into this category. 48+ professional and non-professional researchers has worked together to reverse that while publishing benchmarks for 30+ African languages, evaluations, datasets and open-sourced implementations. – https://www.masakhane.io/

TICO-19: the Translation Initiative for Covid-19 (Paper)
The Translation Initiative for Covid-19 (TICO-19) came together shortly after the beginning of the Covid-19 pandemic with the aim of enabling the translation of content related to COVID-19 into a wide range of languages. It is a unique collaboration between several academic (Carnegie Mellon University, George Mason University, Johns Hopkins University) and industry players (Amazon, Appen, Facebook, Google, Microsoft, Translated) and Translators without Borders. TICO-19’s objective is to prepare data for a variety of the world’s languages to be used by professional translators and for training Machine Translation (MT) models in Covid-19 domain. – https://tico-19.github.io/
Here goes the papers that caught my eye during the conference. If you have more paper suggestions similar to these, please don’t hesitate to drop me a note.
Sparse Transcription - S. Bird (Paper, Video)
- Approach transcription as observing, not data creation
- Phone recognition for transcripton is not enough. We need lexical information.
- Traditionally spoken languages are translated first, not literally translated
- Leverage keyword spotting instead of ASR
- Paper includes more on sparse transcription model:
- data structure
- 8 transcription tasks
- transcription workflows
- evaluations
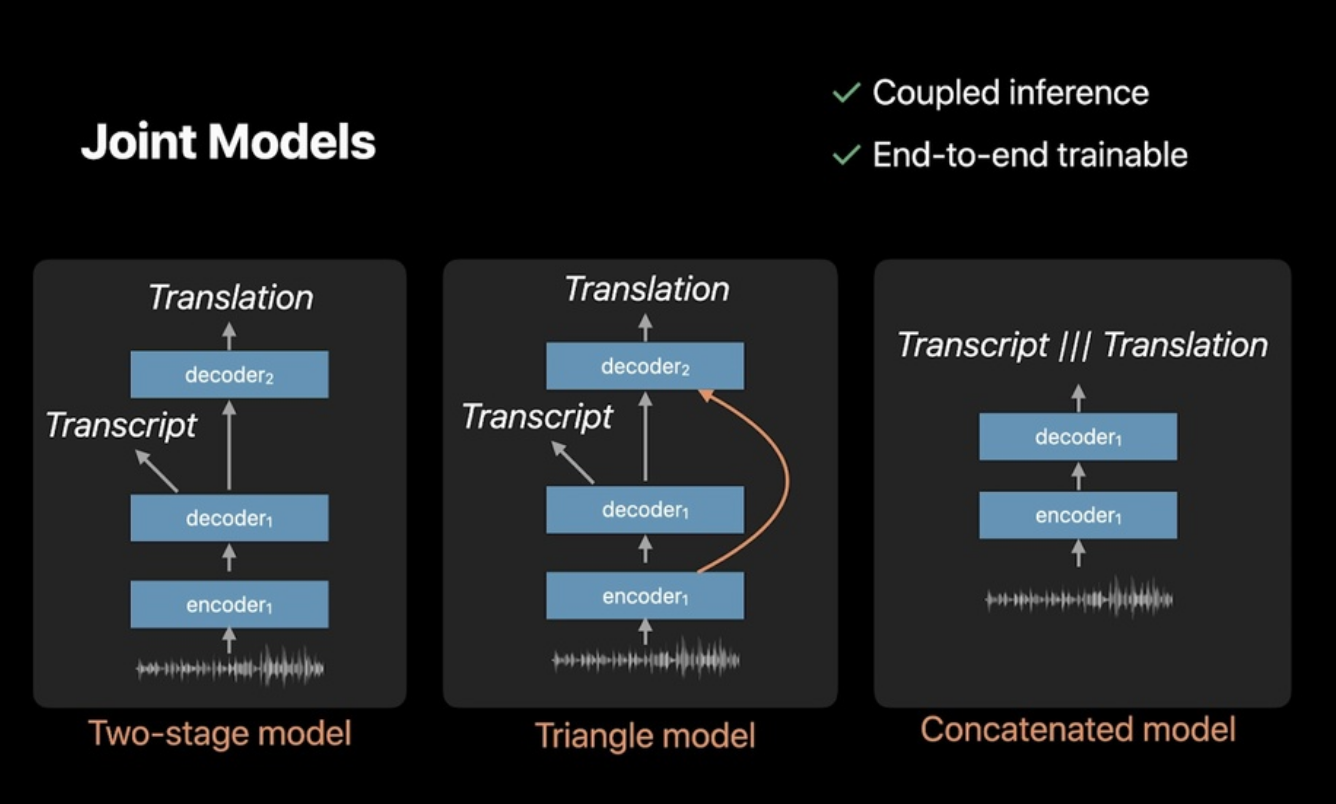
Consistent Transcription and Translation of Speech – Sperber+ (Paper, Video)
- Objective: Obtain both transcript and translation of speech and make them consistent
- For evaluation, WER and BLEU by themselves are not enough because they do not measure consistency between the transcription and translation result.
- Propose metrics to evaluate consistency
- Evaluate on many models: cascaded, direct and joint models
- Data: Must-C Corpus (EN-DE)
- Joint models (see below) perform the best in terms of WER, BLEU and consistency
- Best of the best: Two-stage model
- Conclusion: Coupled inference and end-2-end training are desirable in speech translation
ChrEn: Cherokee-English Machine Translation for Endangered Language Revitalization – Zhang+ (Paper, Video)
- Obtain best possible model for bidirectional Cherokee-English MT
- Data: 14k parallel sentences (collected as part of the work)
- Results:
- RNN performs better than transformer
- Out of domain gives half the BLEU
- Using BERT on En-Chr direction +0.5% BLEU
- SMT performs better with out-of-domain data
- A lot of monolingual data doesn’t necessarily help - 5K backtranslated sentences give the best performance
- Cross-lingual transfer: * Unrelated languages help * Evaluated transferring vs. multilingual
- Code and data
Can Automatic Post-Editing Improve NMT? – Chollampatt+ (Paper, Video)
- Created new large-scale EN-DE post-editing corpus from movie subtitles
- SubEdits: 161k triply-parallel corpus: src, mt, post-edit(pe)
- open source
- How much improvement on NMT from the usage of post-editing data?
- BLEU: 61.88 -> 64.53 (+3%)
- Human evaluation scores: 3.4 -> 3.9 (out of 5)
- Improvements start from a training corpus size of 25k triplets
- How much artifical APE data help?
- Artificial: take a parallel corpus, machine translate it, assume tgt as post-edit
- SubEscape corpus: 5.6 M triplets
- Marginal improvement (+0.06 BLEU)
- Artificial data doesn’t help by itself
- Post-editing data improves only if it’s in the domain
- Data: Post-editing Datasets by Rakuten (PEDRa)
Simulated multiple reference training improves low-resource machine translation – Khayrallah+ (Paper, Video)
- Data augmentation for NMT by paraphrasing of target side sentences
- Record increase in quality (more than what you get from back-translation)
- State that paraphrasers are getting more and more available for languages.
- PRISM paraphraser in 39 languages
- Data
BLEU might be Guilty but References are not Innocent – Freitag+ (Paper, Video)
- Observation: BLEU doesn’t show the improvement obtained from techniques like back-translation
- Propose: When BLEU seems to act weird, revise the reference translations
- Detected problem: Reference translations tend to be in translationese
- := imitating the structure of the source sentence
- MT model strives to be the most average translationese
- When you improve fluency with methods like back-translation or automatic post-editing, BLEU conditioned on translationese doesn’t show the improvement even though human evaluations do
- Solution: paraphrase the reference sentences